2020 Spring 6.824 Lab2A: Raft Leader Election笔记
Raft 使用一种心跳机制来触发Leader Election,通过选举一个Leader,然后给予他全部的管理复制日志的权力来实现一致性。本章将实现Lab2A,详细介绍如何实现Raft算法里的Leader Election,以及该部分的可靠性。
2020 Spring 6.824 Lab2A:Raft Leader Election笔记
0. Lab2A要干啥
- 我们要解决什么问题?
一致性共识问题。
- 采用了什么方案。
拜占庭方案,Raft改编自Paxos算法,为了解决Paxos难于理解且难于实现的问题。
先看一遍论文原文:https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
这个中文翻译很不错,我的注释很多都是参照里面:https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
这个Raft可视化也不错,如果看不下论文可以先看一遍这个:http://thesecretlivesofdata.com/raft/
本章代码地址:https://github.com/keleqnma/6.824-notes-codes/tree/master/src/raft
我还是建议想学6.824的同学仔仔细细去看一遍论文原文,之前我看了一些文章,搞懂了Raft大致是什么原理,怎么工作的,但是要实现它必须还是要去看原文,有很多细节需要注意。
1. 测试代码&Config代码逻辑
1.1. 测试Config初始化
2A总共有两个test,现在以test2A为例说一下raft的初始化
func TestInitialElection2A(t *testing.T) {
servers := 3
cfg := make_config(t, servers, false)
defer cfg.cleanup()
······
}测试代码注册了一个config(传入参数为3),config注册了三个Raft节点,并完成一系列初始化操作:初始化RPCNet,初始化ApplyErr(对应节点在接收commit时报的错),初始化logs(用于存储key-value结构的Entry数据),连接状态等等,比如这个启动Raft节点的代码:
//
// start or re-start a Raft.
// if one already exists, "kill" it first.
// allocate new outgoing port file names, and a new
// state persister, to isolate previous instance of
// this server. since we cannot really kill it.
//
func (cfg *config) start1(i int) {
cfg.crash1(i)
// a fresh set of outgoing ClientEnd names.
// so that old crashed instance's ClientEnds can't send.
cfg.endnames[i] = make([]string, cfg.n)
for j := 0; j < cfg.n; j++ {
cfg.endnames[i][j] = randstring(20)
}
// a fresh set of ClientEnds.
ends := make([]*labrpc.ClientEnd, cfg.n)
for j := 0; j < cfg.n; j++ {
ends[j] = cfg.net.MakeEnd(cfg.endnames[i][j])
cfg.net.Connect(cfg.endnames[i][j], j)
}
cfg.mu.Lock()
// a fresh persister, so old instance doesn't overwrite
// new instance's persisted state.
// but copy old persister's content so that we always
// pass Make() the last persisted state.
if cfg.saved[i] != nil {
cfg.saved[i] = cfg.saved[i].Copy()
} else {
cfg.saved[i] = MakePersister()
}
cfg.mu.Unlock()
// listen to messages from Raft indicating newly committed messages.
applyCh := make(chan ApplyMsg)
go func() {
for m := range applyCh {
err_msg := ""
if m.CommandValid == false {
// ignore other types of ApplyMsg
} else {
v := m.Command
cfg.mu.Lock()
for j := 0; j < len(cfg.logs); j++ {
if old, oldok := cfg.logs[j][m.CommandIndex]; oldok && old != v {
// some server has already committed a different value for this entry!
err_msg = fmt.Sprintf("commit index=%v server=%v %v != server=%v %v",
m.CommandIndex, i, m.Command, j, old)
}
}
_, prevok := cfg.logs[i][m.CommandIndex-1]
cfg.logs[i][m.CommandIndex] = v
if m.CommandIndex > cfg.maxIndex {
cfg.maxIndex = m.CommandIndex
}
cfg.mu.Unlock()
if m.CommandIndex > 1 && prevok == false {
err_msg = fmt.Sprintf("server %v apply out of order %v", i, m.CommandIndex)
}
}
if err_msg != "" {
log.Fatalf("apply error: %v\n", err_msg)
cfg.applyErr[i] = err_msg
// keep reading after error so that Raft doesn't block
// holding locks...
}
}
}()
rf := Make(ends, i, cfg.saved[i], applyCh)
cfg.mu.Lock()
cfg.rafts[i] = rf
cfg.mu.Unlock()
svc := labrpc.MakeService(rf)
srv := labrpc.MakeServer()
srv.AddService(svc)
cfg.net.AddServer(i, srv)
}首先在RPCNet里注册当前节点和其他节点的连接(ends),并初始化Persister(用于存储raftstate和snapshot的),启动一个Goroutine监听,把监听到的数据和cfg上其他节点进行对比,如果不一样就报错,然后对比commit的序号,如果不符就报错,并且把错误记录进ApplyErr。
随后创建一个RaftServer,创建Server的具体代码如下(这也是我们要实现的地方):
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (2A, 2B, 2C).
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
return rf
}随后用raft server初始化一个service,初始化一个空server,把该service添加到server里,再在RPCNet里添加该Server。
1.2. 测试要点
2A的测试比较简单,只有两个。
TestA是检测初始化之后有没有顺利选举出一个Leader,检测term的变化(选举出新Leader后term要加一),然后检测在网络情况不变的情况下,原有Leader有没有被罢黜,term有没有变化:
func TestInitialElection2A(t *testing.T) {
servers := 3
cfg := make_config(t, servers, false)
defer cfg.cleanup()
cfg.begin("Test (2A): initial election")
// is a leader elected?
cfg.checkOneLeader()
// sleep a bit to avoid racing with followers learning of the
// election, then check that all peers agree on the term.
time.Sleep(50 * time.Millisecond)
term1 := cfg.checkTerms()
if term1 < 1 {
t.Fatalf("term is %v, but should be at least 1", term1)
}
// does the leader+term stay the same if there is no network failure?
time.Sleep(2 * RaftElectionTimeout)
term2 := cfg.checkTerms()
if term1 != term2 {
fmt.Printf("warning: term changed even though there were no failures")
}
// there should still be a leader.
cfg.checkOneLeader()
cfg.end()
}TestB是检测初始化之后有没有顺利选举出一个Leader,然后把原有的Leader断连,检测有没有选举出新Leader,然后再把原有的Leader重连,看看会不会产生两个Leader,然后把包括leader在内的两个节点断连,看看是不是无leader产生(raft算法只能在大多数节点正常工作的情况下运行),再重新连接回两个断连的节点,检测有没有选举出新Leader:
func TestReElection2A(t *testing.T) {
servers := 3
cfg := make_config(t, servers, false)
defer cfg.cleanup()
cfg.begin("Test (2A): election after network failure")
leader1 := cfg.checkOneLeader()
// if the leader disconnects, a new one should be elected.
cfg.disconnect(leader1)
cfg.checkOneLeader()
// if the old leader rejoins, that shouldn't
// disturb the new leader.
cfg.connect(leader1)
leader2 := cfg.checkOneLeader()
// if there's no quorum, no leader should
// be elected.
cfg.disconnect(leader2)
cfg.disconnect((leader2 + 1) % servers)
time.Sleep(2 * RaftElectionTimeout)
cfg.checkNoLeader()
// if a quorum arises, it should elect a leader.
cfg.connect((leader2 + 1) % servers)
cfg.checkOneLeader()
// re-join of last node shouldn't prevent leader from existing.
cfg.connect(leader2)
cfg.checkOneLeader()
cfg.end()
}2. 定义结构
2.1. Raft State

type Raft struct {
mu sync.Mutex // lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
role Role //当前服务器的角色
currentTerm int //服务器已知最新的任期(在服务器首次启动的时候初始化为0,单调递增)
electionTimer *time.Timer // 发起选举的计时器
appendEntriesTimers []*time.Timer // appendEntries的计时器,2A中用来发心跳
applyTimer *time.Timer // apply日志的计时器,2A用不到
notifyApplyCh chan struct{}
stopCh chan struct{}
voteFor int // 当前任期内收到选票的候选者id
applyCh chan ApplyMsg
logEntries []LogEntry // 日志条目;每个条目包含了用于状态机的命令,以及领导者接收到该条目时的任期(第一个索引为1),lastSnapshot 放到 index 0
commitIndex int // 已知已提交的最高的日志条目的索引(初始值为0,单调递增)
lastApplied int // 已经被应用到状态机的最高的日志条目的索引(初始值为0,单调递增)
//leader需要保存的
nextIndex []int // 对于每一台服务器,发送到该服务器的下一个日志条目的索引(初始值为领导者最后的日志条目的索引+1)
matchIndex []int // 对于每一台服务器,已知的已经复制到该服务器的最高日志条目的索引(初始值为0,单调递增)
lastSnapshotIndex int // 快照中的 index
lastSnapshotTerm int
}
2.2 RequestVote RPC

type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int // 候选人的任期号
CandidateId int // 请求选票的候选人的 Id
LastLogIndex int // 候选人的最后日志条目的索引值
LastLogTerm int // 候选人最后日志条目的任期号
}
type RequestVoteReply struct {
// Your data here (2A).
Term int // 当前任期号,以便于候选人去更新自己的任期号
VoteGranted bool // 候选人赢得了此张选票时为真
}3. 逻辑实现
3.1. Raft初始化
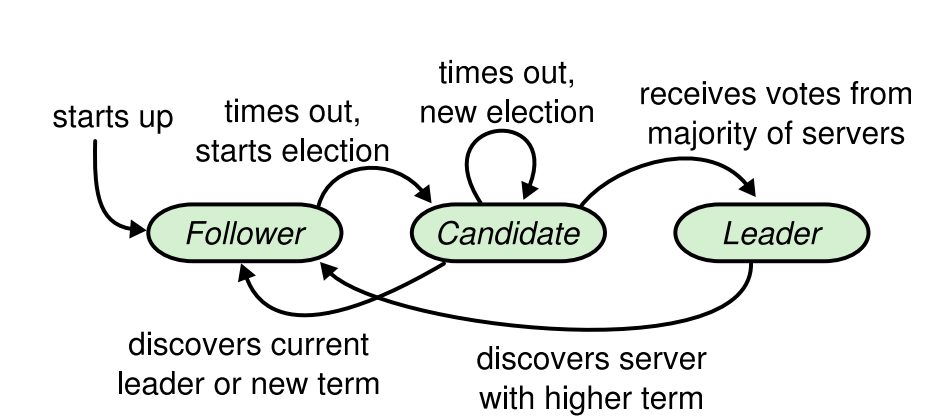

每个Raft Server初始化时都是Follower状态,term为0.
Raft server初始化一个electionTimer计时器(时间从150ms-300ms不等),如果在计时器完成之前,收到了Candidate服务器发送的投票请求(RequestVote),或者是收到了leader发送的心跳(AppendEntries),则刷新计时器,继续维持Follower状态。
如果没有收到,即选举超时,则转变为Candidate,发起投票。
这里和大多数人一样,将选举计时行为封装为一个loop(raft共有三个loop,electionLoop,appendEntriesLoop,applyLogLoop,这三个时间都是由超时驱动的)。
func (rf *Raft) electionLoop() {
for {
select {
case <-rf.stopCh:
return
case <-rf.electionTimer.C:
rf.startElection()
}
}
}3.2. 发起选举,选出Leader
3.2.1. 发出选举要求
要开始一次选举过程,跟随者先要增加自己的当前任期号并且转换到Candidate。然后它向集群中的其他节点发送RequestVoteArgs来给自己投票。直到以下任意发生:
- 赢得选举
当一个候选人从整个集群的大多数服务器节点获得了针对同一个任期号的选票,那么他就赢得了这次选举并成为领导人。每一个服务器最多会对一个任期号投出一张选票,按照先来先服务的原则。要求大多数选票的规则确保了最多只会有一个候选人赢得此次选举。一旦候选人赢得选举,他就立即成为领导人。然后他会向其他的服务器发送心跳消息来建立自己的权威并且阻止新的领导人的产生。
- 其他Raft节点成为Leader
在等待投票的时候,候选人可能会从其他的服务器接收到声明它是领导人的附加日志项 RPC。如果这个领导人的任期号(包含在此次的 RPC中)不小于候选人当前的任期号,那么候选人会承认领导人合法并回到跟随者状态。 如果此次 RPC 中的任期号比自己小,那么候选人就会拒绝这次的 RPC 并且继续保持候选人状态。
- No one wins
如果有多个跟随者同时成为候选人,那么选票可能会被瓜分以至于没有候选人可以赢得大多数人的支持。当这种情况发生的时候,每一个候选人都会超时,然后通过增加当前任期号来开始一轮新的选举。然而,没有其他机制的话,选票可能会被无限的重复瓜分。
Raft 算法使用随机选举超时时间的方法来确保很少会发生选票瓜分的情况,就算发生也能很快的解决。为了阻止选票起初就被瓜分,选举超时时间是从一个固定的区间(例如 150-300 毫秒)随机选择。这样可以把服务器都分散开以至于在大多数情况下只有一个服务器会选举超时;然后他赢得选举并在其他服务器超时之前发送心跳包。同样的机制被用在选票瓜分的情况下。每一个候选人在开始一次选举的时候会重置一个随机的选举超时时间,然后在超时时间内等待投票的结果;这样减少了在新的选举中另外的选票瓜分的可能性。
3.2.2. 接收选举要求
// 选举人的term小于当前服务器的term,拒绝投票
if req.Term < rf.currentTerm {
return
}
// 已经选举成功,拒绝投票
if rf.role == Leader {
return
}
// 已经投票给当前候选人
if rf.voteFor == req.CandidateId {
reply.VoteGranted = true
return
}
// 如果已经投票,且对象不是当前候选人,拒绝投票
// 但如果当前服务器不是follwer,且选举人的term不小于当前服务器的term,则它会转投给选举人
if rf.voteFor != voteForNobody && rf.voteFor != req.CandidateId && rf.role == Follower {
return
}
// 候选人最后一条日志的term小于当前服务器最后一条日志的term, 或者候选人最后一条日志的index小于当前服务器最后一条日志的index(即log记录冲突),拒绝投票
if lastLogTerm > req.LastLogTerm || (req.LastLogTerm == lastLogTerm && req.LastLogIndex < lastLogIndex) {
return
}
// 将自身的term调整为和候选人一致
rf.currentTerm = req.Term
// 投票给候选人
rf.voteFor = req.CandidateId
reply.VoteGranted = true
rf.changeRole(Follower)
// 刷新计时器
rf.resetElectionTimer()
rf.log("vote for:%d", req.CandidateId)3.3. 选举完成,Leader发送心跳
2A里其实没啥好说的,实测就算你不写心跳也能过那两个test,算是测试的设计疏漏吧,appendentries我会放到2B里一起讲。
4. 算法可靠性&一致性分析
4.1. Leader节点崩溃
Leader崩溃后,Follower节点将不再收到心跳,计时器到时后Follower节点会重新进行选举。
4.2. Follower节点/Candidate节点崩溃
Leader节点发现发给某个follower节点的心跳超时后,Leader节点会无限重发。Raft 的 RPCs 都是幂等的,所以这样重试不会造成任何问题。例如一个跟随者如果收到附加日志请求但是他已经包含了这一日志,那么他就会直接忽略这个新的请求。
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。例如,“setTrue()”函数就是一个幂等函数,无论多次执行,其结果都是一样的,更复杂的操作幂等保证是利用唯一交易号(流水号)实现.
4.3. 如何保证选出一个稳定的Leader?
要求一个Leader只有拿到大于一半节点的投票才能当选,且每个节点在一次任期中只能投给一个Candidate,保证了每次term里只会选出一个Leader。
Raft 的要求之一就是安全性不能依赖时间:整个系统不能因为某些事件运行的比预期快一点或者慢一点就产生了错误的结果。但是,可用性(系统可以及时的响应客户端)不可避免的要依赖于时间。例如,如果消息交换比服务器故障间隔时间长,候选人将没有足够长的时间来赢得选举;没有一个稳定的Leader,Raft 将无法工作。
所以我们要保证:广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF)
在这个不等式中,广播时间指的是从一个服务器并行的发送 RPCs 给集群中的其他服务器并接收响应的平均时间;选举超时时间是在 选举的超时时间限制;平均故障间隔时间就是对于一台服务器而言,两次故障之间的平均时间。广播时间必须比选举超时时间小一个量级,这样领导人才能够发送稳定的心跳消息来阻止跟随者开始进入选举状态;通过随机化选举超时时间的方法,这个不等式也使得选票瓜分的情况变得不可能。选举超时时间应该要比平均故障间隔时间小上几个数量级,这样整个系统才能稳定的运行。当领导人崩溃后,整个系统会大约相当于选举超时的时间里不可用;我们希望这种情况在整个系统的运行中很少出现。
广播时间和平均故障间隔时间是由系统决定的,但是选举超时时间是我们自己选择的。Raft 的 RPCs 需要接收方将信息持久化的保存到稳定存储中去,所以广播时间大约是 0.5 毫秒到 20 毫秒,取决于存储的技术。因此,选举超时时间可能需要在 10 毫秒到 500 毫秒之间。大多数的服务器的平均故障间隔时间都在几个月甚至更长,很容易满足时间的需求。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!